· 7 min read
Running models using NPU with Copilot+ PC
Leverage the power of the NPU with this getting started in Python guide to running Qualcomm AI models on Snapdragon Elite X devices using the QNNExecutionProvider.

Introduction
Recently I have been exploring models to run locally from Qualcomm® library on the AI Hub to try something out and run a small model such as Super Resolution that is designed to upscale images to a higher resolution. The challange came when trying to explicitly run the model on the NPU (Neural Processing Unit) instead of the CPU - which I have managed to get working recently. This post shares how to do that, if you are struggling and want to learn about local models too.
So lets get started - but to warn you, I’m not a Python guy, I mainly dotnet C# and Typescript but I’m learning something new since alot of samples using AI start with Python. There was a new Local On-Device AI in Copilot+ PCs Explained | Microsoft Mechanics video launched recently that highlights the capabilities of Snapdragon based devices to give you a bit of a background, bear in mind, I dont have a Surface device, I have a Lenono Slim 7x Copilot+ PC.
Why not use a studio
During my time research on how to utilise the core feature of a Copilot+ PC, the 40 TOPS NPU, I found that many SDKs i.e. Windows App SDK including Windows Copilot Runtime, Onnxruntime-GenAI library, Samples, and so on, are not yet ready for using the local devices NPU. Typical me to get a device that bleeding edge that software has yet to catch up. Even products for LLM/Model studios for running models have yet to support NPUs. I suspect, if you read this towards end of 2024 this might be a different story.
I’ve tried the following studios for running models, typically, LLM models and they work BUT, none of them yet utilise the NPU.
- LM Studio
- AI Toolkit
- Anaconda AI Studio
These are great tools, most in beta or preview and I havent found one yet that runs using the Qualcomm Hexagon NPU.
Setup with Python
Lets get started, I’m not going to do much of a step by step guide here but this is my setup to set that foundation. I have installed,
- Miniconda specically the Windows x64 version. At the time of writing seen many warnings about ARM64 dependencies need to catch up. So you may want to explore the ARM version, if your wondering what this is, its like NVM but for python allowing you to create contained environments for version, dependencies etc so you can switch versions easily.
- Setup an environment running Python 3.11
- Activate the environment accordingly.
I thank Fabian Williams for the recommendation, its might easier to jump versions.
At this point don’t yet start installing packages with pip.
Additonal Software
Before I get into this, I need to thank Qualcomm AI Support thorugh their Slack channels, super quick and responsive to help me unlock why I couldnt get a key component running.
Next your going to need:
- Visual Studio 2022 with the C++ development tools installed. Now when I was working on this I am not fully sure this is needed, but as part of getting this working it was recommended.
- Qualcomm® AI Engine Direct SDK - you will need some key files from this SDK. Signup and download here Qualcomm® AI Engine Direct SDK | Software Centre
Getting Model working starting with the CPU
So for this example, you can get Snapdragon Elite X optimised models from the Qualcomm®‘s AI Hub download the - QuickSRNetLarge-Quantized AI Model. This model is designed to upscale images to a higher resolution up to 4x the orignal size. I felt this was a good starting place. Download the model and keep note of the path.
Next we need a sample, I wrote this with the help of GitHub Copilot, to get an image and format, convert and size according to the specifications of the model, Im using a 128px x 128px image of some rocks on a beach.

First install the phython modules:
pip install onnx onnxruntime numpy pillowthen either save the following script, or use a Jupyter Notebook (what I use) to run the Python script:
import onnx
import onnxruntime as ort
import numpy as np
from PIL import Image
import sys
# Install - pip install onnx onnxruntime onnxruntime-qnn pillow
def preprocess_image(image_path):
# Load image
image = Image.open(image_path).convert('RGB') # Convert to grayscale
image = image.resize((128, 128)) # Resize to the required input size
image_data = np.array(image).astype(np.uint8)
image_data = image_data.transpose(2, 0, 1) # Change data layout from HWC to CHW
image_data = np.expand_dims(image_data, axis=0) # Add batch dimension
return image_data
def postprocess_output(output_data):
# Remove batch dimension and change data layout from CHW to HWC
output_image = output_data.squeeze().transpose(1, 2, 0)
# Convert to uint8
output_image = output_image.astype(np.uint8)
return output_image
def main(image_path):
# Check available providers
available_providers = ort.get_available_providers()
print("Available providers:", available_providers)
# Load the ONNX model
model_path = r"C:\\ai\\models\\quicksrnetlarge_quantized.onnx" # Ensure this file exists in the correct path
providers = ['CPUExecutionProvider']
ort_session = ort.InferenceSession(model_path, providers=providers)
# Prepare input data
input_name = ort_session.get_inputs()[0].name
input_data = preprocess_image(image_path)
# Run the model
result = ort_session.run(None, {input_name: input_data})
# Post-process the output
output_image = postprocess_output(result[0])
# Save the output image
output_image = Image.fromarray(output_image)
output_image.save("output_image_notebook.png")
print("Output image saved as output_image_notebook.png")
if __name__ == "__main__":
main('example_image_128.jpg')if you run this, its a very small model, it will run in Milliseconds, so will be fast.
Note: If you run
pip install onnxruntime-qnnbefore doing installing the dependenies, which I did, you will need to install and re-install the package. For a while, the “QNNExecutionProvider” was not showing up as available providers in the sample code provided later.
Your output should look like this:
Available providers: ['AzureExecutionProvider', 'CPUExecutionProvider']
Output image saved as output_image_notebook.png
Hopefully, this will run successfully for you, you should get an upscaled output image of 512px x 512px.
Now OK, may not feel super implressive, but you could slice and dice up a larger one into tiles for example the dimentions of the input and run multiple times then stitch together. Bit beyond this example though.
The key aspect of choosing where the model runs is the CPUExecutionProvider which runs on the CPU.
Enhancing model to utilise the NPU
So you can tweak this script to run on the NPU, how can you check, you should see a small spike in Task Manager.
Install the python module
pip install qnnxruntime-qnnNext from the SDK, we need to find the QnnHtp.dll file in the C:\Qualcomm\AIStack\QAIRT\2.26.0.240828\lib\arm64x-windows-msvc directory.
I copied this into a common location, then modify the python script accordingly:
change:
providers = ['CPUExecutionProvider']
ort_session = ort.InferenceSession(model_path, providers=providers)to:
execution_provider_option = {
"backend_path": f"C:\\ai\\qcdll\\QnnHtp.dll",
"session.enable_htp_fp16_precision": "1",
"htp_performance_mode": "high_performance",
}
# Use QNNExecutionProvider regardless of the available providers
providers = ['QNNExecutionProvider']
ort_session = ort.InferenceSession(model_path, providers=providers, provider_options=[execution_provider_option])Re-run the model and your output should look like this:
Available providers: ['QNNExecutionProvider', 'AzureExecutionProvider', 'CPUExecutionProvider']
Output image saved as output_image_notebook.png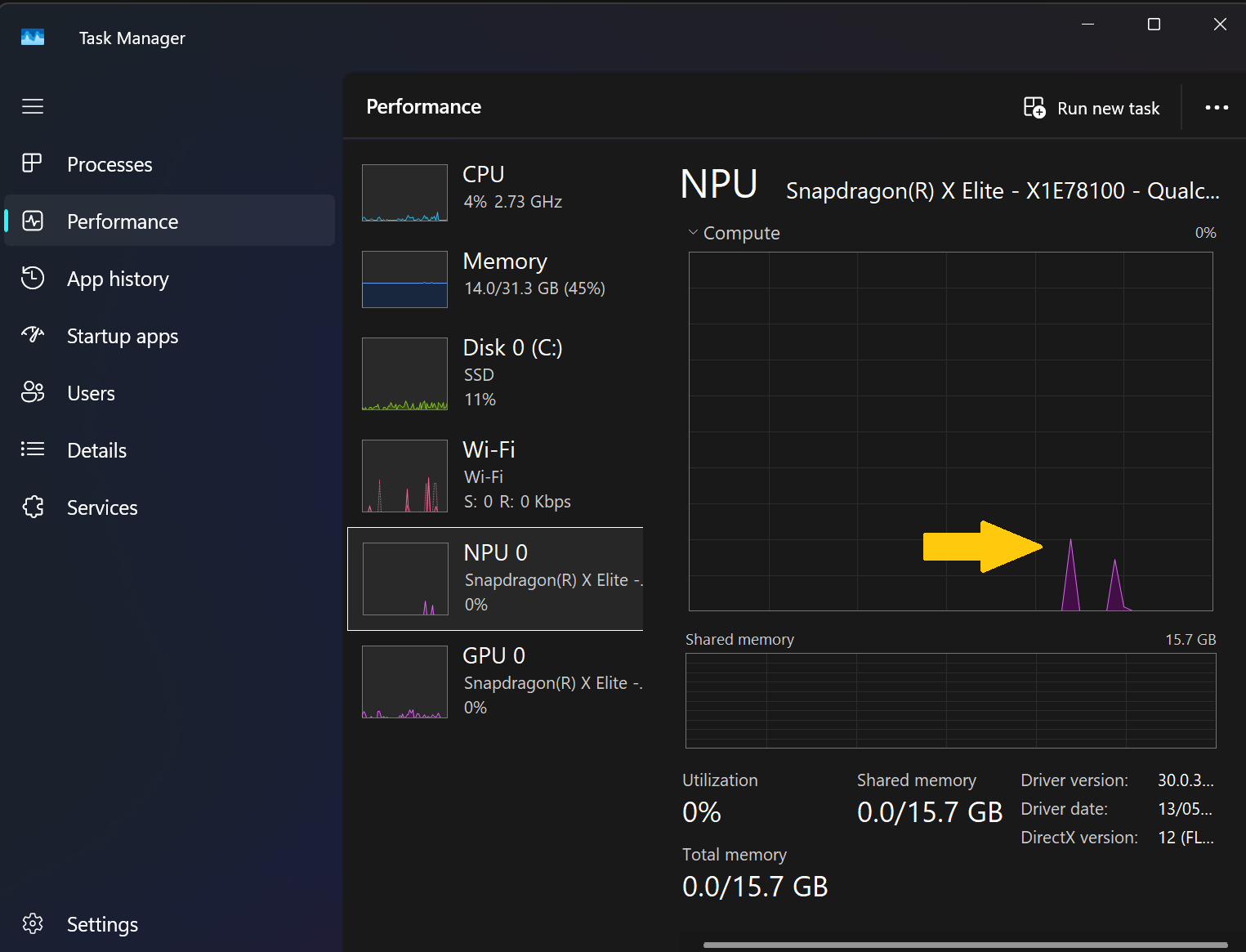
Wahoo!!
Conclusion
I personally, did ALOT of playing and research to get this up and running to have SOMETHING using the NPU, but now I have the QNNExecutionProvider working, I can explore more dense models to run. I am keen to explore this further with LLMs when the Windows Copilot Runtime and Windows SDK and/or the onnxruntime-genai library get QNN support - I literally have watches on the relevant repos to monitor when this happens.
It wont be long until these libraries are released and when that happens - I feel we will have an explosion of samples, demos, new apps using these local models.
Resources
The following resource might be useful for you to learn further:
- Qualcomm® AI Hub
- Qualcomm® Slack Community
- Qualcomm® GitHub Repo - note these examples/demos will utilise their cloud devices not the local ones.
- QNN EP | Windows on Snapdragon Docs
- deeplearning.ai if you want significantly more technical detail on how AI models work.
- Copilot+ PCs Developer Guide | Microsoft Learn
Enjoy!